
The History of Big Data: Its Origins and Evolution
Big Data has evolved from the early days of computing to a critical component of modern technology. Understanding its history helps us appreciate its impact on decision-making and innovation.
Big Data has become a buzzword in the tech industry, but its roots can be traced back to the early days of computing. The term ‘Big Data’ refers to the vast volumes of data generated every second, and the technologies that enable its processing and analysis. Understanding its history helps us appreciate how far we’ve come and where we’re headed.
The Early Days of Data
In the 1960s and 1970s, data was primarily stored on mainframe computers. Organizations began to realize the importance of data for decision-making, leading to the development of databases. However, the data was limited in volume and complexity, and traditional data processing methods sufficed.
The Rise of the Internet
The 1990s saw the advent of the internet, which drastically changed the landscape of data generation. With the explosion of websites and online services, data began to grow exponentially. Companies like Google and Amazon emerged, leveraging this data to enhance user experiences and drive business decisions.
The Big Data Revolution
By the early 2000s, the term ‘Big Data’ was coined to describe the challenges and opportunities presented by the massive amounts of data being generated. Technologies such as Hadoop and NoSQL databases were developed to handle unstructured data, allowing organizations to store and analyze data at scale.
Current Trends and Future Directions
Today, Big Data is at the forefront of technological innovation. Machine learning and artificial intelligence are being integrated with Big Data analytics to derive insights and predictions from complex datasets. As we move forward, the focus will be on ethical data use, privacy concerns, and the development of more sophisticated analytical tools.
In conclusion, the evolution of Big Data reflects the changing dynamics of technology and society. As we continue to generate and analyze data, understanding its history will be crucial in navigating the future of data-driven decision-making.
Más en General.
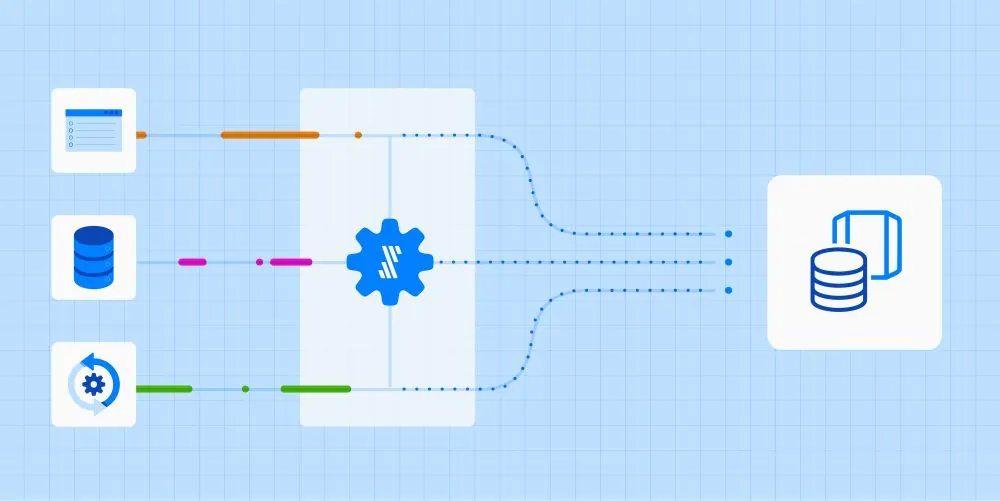
From Legacy to Modern Data Stack: Why Companies Are Making the Shift
Organizations are increasingly recognizing the limitations of traditional data architectures. Legacy systems struggle to meet modern demands, while Modern Data Stacks offer scalability, integration, and governance solutions.

Improve productivity, collaboration, and project management with ClickUp
In an increasingly dynamic business environment, having a comprehensive tool that centralizes tasks, fosters collaboration, and facilitates work organization is key to achieving more efficient teams. At EGOS BI, as an official ClickUp partner, we've seen firsthand how this platform can transform the way companies manage their projects and productivity.

Data drives McDonald's toward a better customer experience
McDonald's improves the customer experience by using data and interactive dashboards to optimize operations at every restaurant.
¿Te resultó útil?
Agenda una discovery call de 30 minutos para hablar de cómo aplicar esto en tu organización.
Agenda discovery call
¿Qué tan AI-ready
está tu data hoy?
Agenda una sesión de 30 minutos con uno de nuestros consultores senior. Salimos con un diagnóstico inicial y un siguiente paso claro.